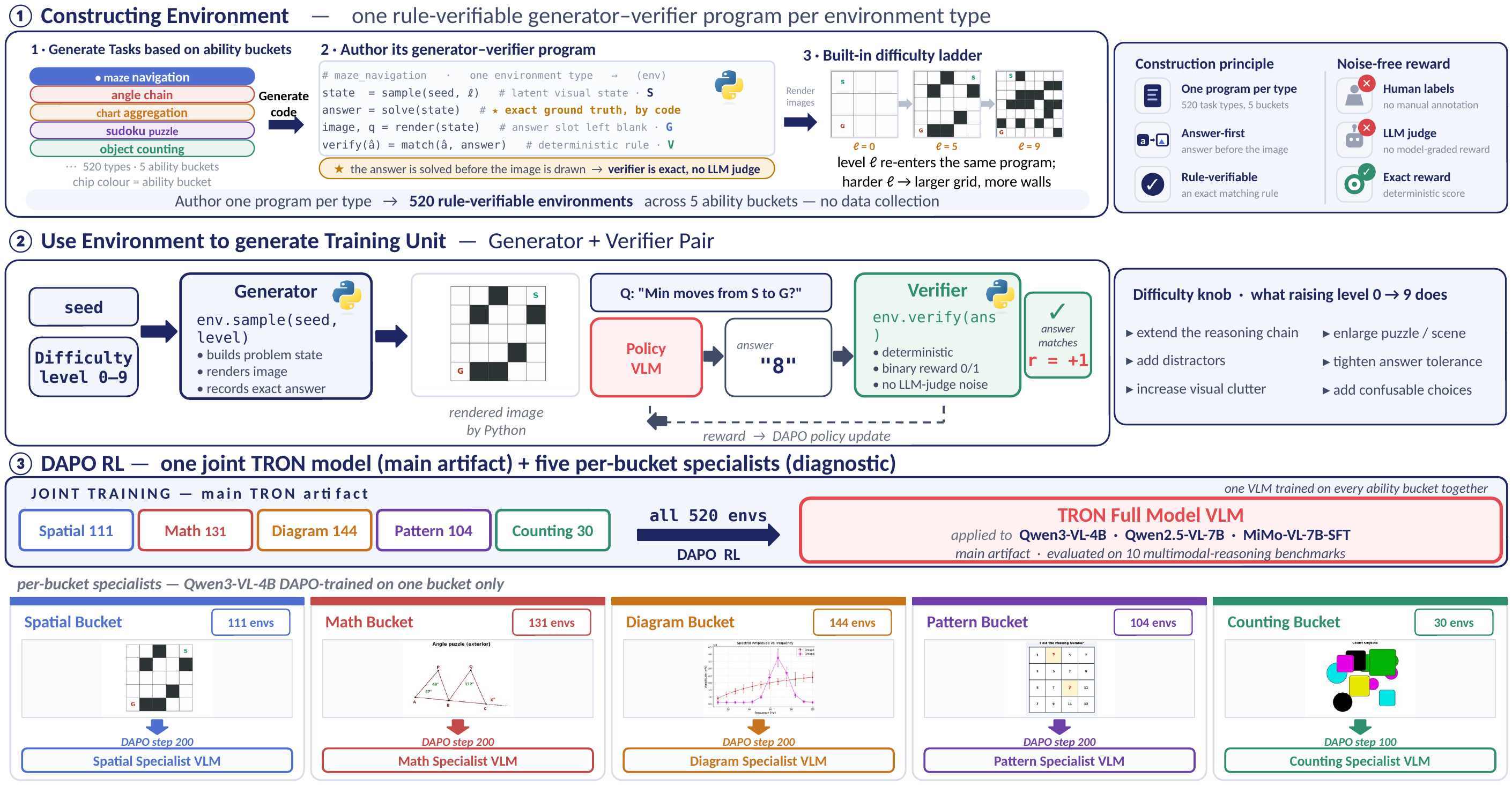
TRON improves three SOTA VLMs on all external benchmarks. The ability-specialist analysis shows transfer is driven by underlying capability, not visual format.
All scores are percentages from VLMEvalKit. Qwen3-4B = Qwen3-VL-4B-Instruct · Qwen2.5-7B = Qwen2.5-VL-7B-Instruct · MiMo-7B = MiMo-VL-7B-SFT. ChartQA Pro for MiMo uses a format-normalized rejudge.
RQ1 · within-bucket
Does a format-defined bucket train its own domain?
Each specialist substantially improves external subtasks whose visual format matches its bucket — Math +11.2 on WeMath angles, Spatial +16.7 on MM-HELIX maze.
→ Visual-format alignment has a clear effect.
RQ2 · cross-bucket
Does capability transfer across formats?
Each specialist also lifts subtasks outside its bucket. Math transfers to MM-HELIX maze (+20.0); Count to MathVerse volume (+7.8); Diagram to PuzzleVQA rect-height (+10.0).
→ Trained capability transfers across formats.
RQ3 · format alone
Is visual format alone sufficient?
The visually-aligned specialist wins only 1 of 10 benchmarks. On MathVerse, Diagram (figure-reading) beats Math; on CharXiv, Math (inference chains) beats Diagram.
→ Cover both format and capability.